I am playing around with BeautifulSoup to scrape data from websites. So I decided to scrape empireonline's website for 100 greatest movies of all time.
Here's the link to the webpage:
https://www.empireonline.com/movies/features/best-movies-2/
I imported the HTML from the site quite alright, I was able to use beautiful soup on it. But when I wanted to get the list of the 100 movie titles, I was getting an empty list.
Here's the code I wrote below.
import requests
from bs4 import BeautifulSoupURL = "https://www.empireonline.com/movies/features/best-movies-2/"response = requests.get(URL)
top100_webpage = response.textsoup = BeautifulSoup(top100_webpage, "html.parser")
movies = soup.find_all(name="h3", class_="jsx-4245974604")
print(movies)
When I ran the code, the result was an empty list. I changed my parsing library to lxml and html5lib but I was still getting the same empty list.
Please how can I resolve this issue?
The data you need renders dynamically, however, it's stored as inline JSON. Therefore, we can extract data from there via regular expression. To do that, must look at the page code (Ctrl+U) to find the matches we need and if there are any, try to get them using regular expressions.
This screenshot shows how the page code looks like and the data we need in it:
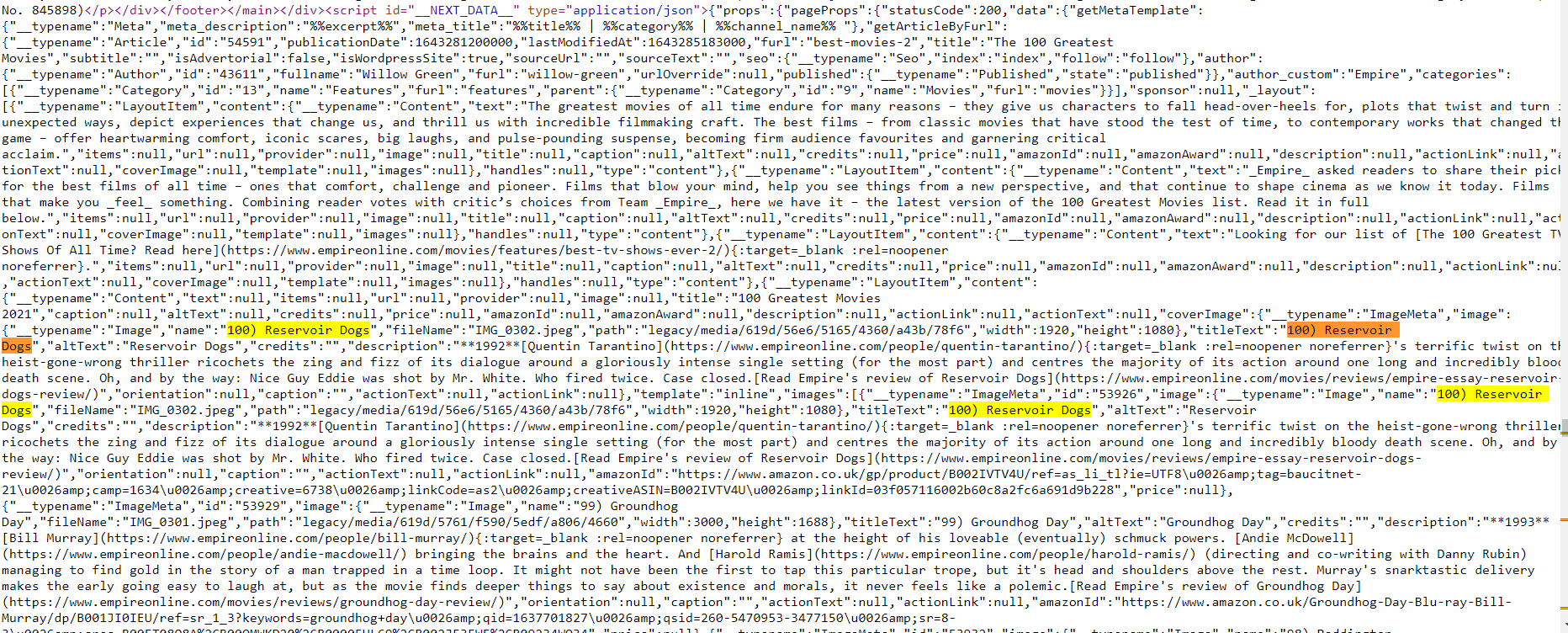
Since there are a lot of matches, we need to use a regular expressions to find the part of the code we need where the list itself will be directly:
#https://regex101.com/r/CqzweN/1
portion_of_script = re.findall("\"Author:42821\"\:{(.*)\"Article:54591\":", str(all_script))
And then we retrieve the list of movies directly:
#https://regex101.com/r/jRgmKA/1
movie_list = re.findall("\"titleText\"\:\"(.*?)\"", str(portion_of_script))
However, we can extract data by converting parsed inline JSON to usable json using json.loads(<variable_that_stores_json_data>) and then access it as we would access a regular dict.
Do not forget that most sites do not like being scraped and the request might be blocked (if using requests as default user-agent in requests library is a python-requests. Additional step could be to rotate user-agent, for example, to switch between PC, mobile, and tablet, as well as between browsers e.g. Chrome, Firefox, Safari, Edge and so on.
You can check the fully working code in online IDE.
from bs4 import BeautifulSoup
import requests, re, json, lxmlheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36",
}html = requests.get("https://www.empireonline.com/movies/features/best-movies-2/", headers=headers, timeout=30)
soup = BeautifulSoup(html.text, "lxml")
all_script = soup.select("script")#https://regex101.com/r/CqzweN/1
portion_of_script = re.findall("\"Author:42821\"\:{(.*)\"Article:54591\":", str(all_script)) #https://regex101.com/r/jRgmKA/1
movie_list = re.findall("\"titleText\"\:\"(.*?)\"", str(portion_of_script)) print(json.dumps(movie_list, indent=2, ensure_ascii=False))
Example output
["100) Reservoir Dogs","99) Groundhog Day","98) Paddington 2","97) Amelie","96) Brokeback Mountain","95) Donnie Darko","94) Scott Pilgrim Vs. The World","93) Portrait Of A Lady On Fire","92) Léon","91) Logan","90) The Terminator","89) No Country For Old Men","88) Titanic","87) The Exorcist","86) Black Panther","85) Shaun Of The Dead","84) Lost In Translation","83) Thor: Ragnarok","82) The Usual Suspects","81) Psycho","80) L.A. Confidential","79) E.T. – The Extra Terrestrial","78) In The Mood For Love","77) Star Wars: Return Of The Jedi","76) Arrival","75) A Quiet Place","74) Trainspotting","73) Mulholland Drive","72) Rear Window","71) Up","70) Spider-Man: Into The Spider-Verse","69) Inglourious Basterds","68) Lady Bird","67) Singin\\' In The Rain","66) One Flew Over The Cuckoo\\'s Nest",# ...
]